When Your Coding Assistant Has Goldfish Memory


I've been experimenting with "vibe coding" tools like Cursor and Claude Code (3.5)—the kind of AI pair programmers that promise to understand your code, suggest fixes, and help you fly through bugs without touching the keyboard too much. In theory, it's magical.
In practice? Well... let me tell you a story.
The Setup
I'm working with a moderately complex Python project—around 500 lines. Its purpose is to load a bunch of configuration files stored in a directory tree. At the top of this tree is a single JSON file, BBL.json, which acts like a map: it lists which configuration files to load and where to find them.
Sounds straightforward. But the current implementation doesn't use BBL.json. Instead, it just scans the entire folder, which is:
- 🐌 Slow
- 🐛 Bug-prone (it loads things it shouldn't)
So I thought, "Why not let my AI pair programmer help fix this?" I dropped into Cursor, fed it the context, and said:
Use the top-level JSON to load only the files listed. Stop scanning the entire folder.
Simple, right?
Where It All Falls Apart: Short-Term Memory Syndrome
At first, it nods enthusiastically. "Yes! I see. Let's use BBL.json as a lookup table."
But within two interactions, it forgets.
Suddenly, it's back to scanning the whole folder again. I remind it gently:
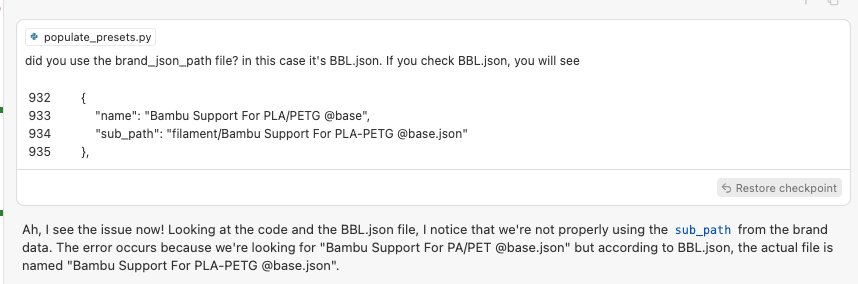
well, I'm not sure if this is a good idea. did you use the top json file (BBL.json in this case) to look up for the correct file path?
did you use the brand_json_path file? in this case it's BBL.json. If you check BBL.json, you will see
It apologizes. It fixes things. And then... it forgets again. This happens over and over. It's like talking to Dory from Finding Nemo.
But even after multiple reminders—screenshots, pasted examples, highlighted instructions—it keeps forgetting.
I end up repeating myself like this:
Did you use brand_json_path? Remember, that's the file to look up the paths. No scanning!
Container Context Amnesia
The code runs inside a Docker Compose cluster. To test the code, the tool needs to add docker compose run web in front of each command, and map the file paths between the host and the docker container.
But Claude/Code/Cursor keeps reverting back to running the command on the host system. When it fails (because required Python packages are only inside the container), it tries to install them on the host. 🤦
Still errors. You can run the command yourself and fix the problems using this docker compose command:
docker compose run web ./manage.py populate_presets data/profiles BBL BBL.json data/output
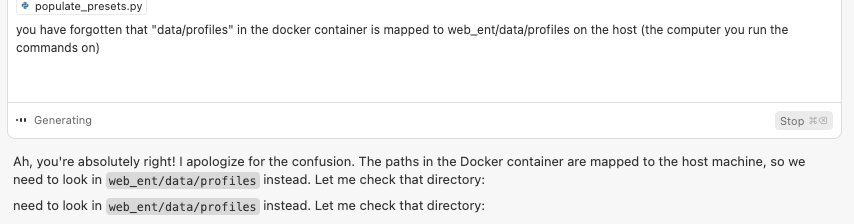
Even worse, it forgets about path mapping between host and container. I try to help:
"data/profiles" in the container = "web_ent/data/profiles" on the host.
Still doesn't stick.
I even copy-paste a full "REMEMBER THIS" preamble into every prompt like a Post-it on a goldfish bowl. Still no memory.
REMEMBER:
- run this command to check your result: `docker compose run web ./manage.py populate_presets data/profiles BBL BBL.json data/output
- "data/profiles" in the docker container is mapped to web_ent/data/profiles on the host (the computer you run the commands on). the python code runs in the docker container, but your linux command runs on the host. So you need to convert all "data/profiles" in the docker compose command output to web_ent/data/profiles to figure out the correct path on the host (the computer you run the commands on). Also the commands following "docker compose" should use "data/profiles" becasue they will run inside the container. Other commands should use web_ent/data/profiles
- Do NOT update the input files or any files in the profile_dir or brand_dir. You should update your code to work with them!
I ended up having to make temporary file changes so that the python code runs on the host, so that the tool can vibe their way without wandering into dead ends too quickly.
use this command to test your command and fix all the errors until the command returns success: cd /Users/kenneth/Projects/tsd-enterprise && source web_ent/env/bin/activate && PYTHONPATH=$PWD/web_ent:obico-server/backend:moonraker DJANGO_SETTINGS_MODULE=settings_ent DATABASE_URL=postgres://tsd-dev:tsd-dev@localhost:6432/tsd-dev python3 web_ent/manage.py … IMPORTANT: - Do NOT update the input files or any files in the profile_dir or brand_dir. You should update your code to work with them!
Death by a Thousand Cuts
It's not just the big things. Small details get lost constantly:
- My backend code is in a backend/ subfolder. Cursor keeps assuming it's in the root.
- .cursorrules file? Ignored.
- It often creates new source trees when it can't find the right one—because it forgot the structure I already explained.
It's like trying to train an intern with a 30-second memory span. A very polite intern. But still.
What I Tried
-
Notebook reminders I wrote out the key details (Docker commands, path mappings, what not to change) and pasted them into every prompt. Still didn't work.
-
Made the code runnable on the host Just so I could give it a more stable test command and say:
"Run this command until it works. Do not change any files in profile_dir or brand_dir. Just fix the code." Again—forgetfulness reigned.
The Real Problem: Context That Doesn't Stick
The core issue here isn't model quality—these are excellent LLMs. It's context retention.
These tools struggle with even medium-complexity workflows that require:
- Understanding a directory hierarchy
- Remembering a source-of-truth file like BBL.json
- Switching mental models between host and container
- Respecting constraints like "don't touch these files"
They forget these things after two replies. Which means I become the memory system.
And if I wanted to be the memory system... I could just read the docs and do it myself.
Where Do We Go from Here?
To be truly useful, vibe coding tools need long-term working memory. The ability to retain key context across a session—things like:
- Project layout
- Runtime environment (e.g., Docker)
- Don't-touch zones
- Key files like BBL.json
Even better would be some kind of "pinned context" system. Something like:
"Hey Claude, always remember that BBL.json maps the config files, and commands run inside Docker Compose with host path mapping."
Until then, vibe coding feels more like vibe nagging. And I'm the one getting nagged.
Have You Experienced This?
If you've run into similar issues—or found workarounds—I'd love to hear your war stories. Leave a comment or hit me up on Twitter (@kennethjiang). Let's share the pain.